
In-Memory Layout of a Program (Process)
Virtual Address Space Overview
Each process runs in its own memory sandbox — the virtual address space.
On a 32-bit system, this is a 4GB block of memory addresses.
- The CPU generates virtual addresses (from
0x00000000to0xFFFFFFFF). - The OS kernel maps these to physical memory via page tables.
- The kernel reserves a dedicated portion of the virtual space for itself.
Typical Split on 32-bit Linux
| Region | Address Range | Size |
|---|---|---|
| User space (process) | 0x00000000 – 0xBFFFFFFF | 3 GB |
| Kernel space | 0xC0000000 – 0xFFFFFFFF | 1 GB |
The following diagram shows this split:
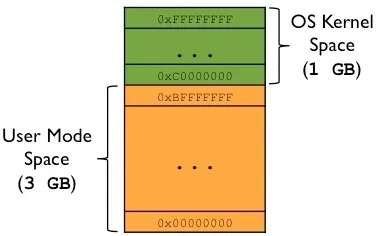
For more details, see the post on Virtual Memory, Paging, and Swapping.
Memory Layout of a Process (User Space)
The diagram below shows how a program (process) looks inside the user mode portion of the virtual address space:
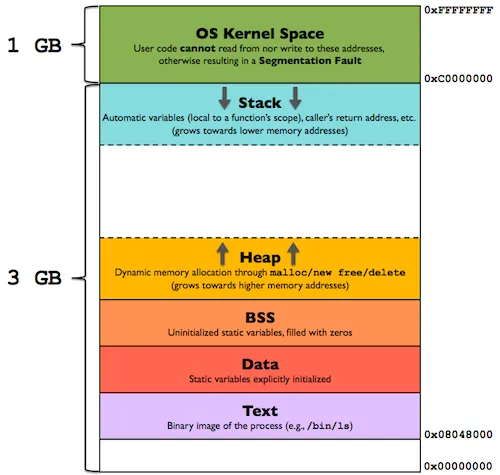
Now let’s examine each segment in detail.
Text Segment (Code)
- Contains executable instructions of the program.
- Often placed below the Heap or Stack to prevent overflows from overwriting it.
- Sharable — only one copy needs to be in memory for frequently used programs (e.g., shells, compilers).
- Read-only / Execute — prevents accidental modification of instructions.
Data Segment (Initialized Data)
Stores global and static variables that are explicitly initialized by the programmer.
Can be further divided into:
| Sub-area | Content | Writable? |
|---|---|---|
.rodata | Read-only data (e.g., string literals) | No |
.data | Read-write initialized data | Yes |
Examples
char s[] = "hello world"; // stored in .data (read-write)
int debug = 1; // stored in .data (read-write)
const char* str = "hello world";
// "hello world" → .rodata
// str (pointer) → .data (because pointer can be modified)
static int i = 10; // stored in .dataThe Data segment is not read-only in general — variable values can change at runtime.
BSS Segment (Uninitialized Data)
Stands for “Block Started by Symbol” (an ancient assembler term).
Contains global and static variables that are:
- Initialized to zero, or
- Not explicitly initialized at all.
- The OS kernel zeros out this segment before the program starts.
- Read-Write.
Heap
- Used for dynamic memory allocation (malloc, new, etc.).
- Begins at the end of the BSS segment.
- Grows upward (toward higher addresses).
- Managed by malloc/free, brk, sbrk.
- Shared by all shared libraries and dynamically loaded modules.
Stack
- Stores the program stack (LIFO structure).
- Located in higher memory addresses, just below the kernel space.
- On x86, it grows downward (toward lower addresses).
- Contains stack frames — one per function call.
Each stack frame includes:
- Automatic (local) variables
- Function parameters
- Return address (to the caller)
This is how recursive functions work: each call gets a new, independent stack frame.
A stack pointer register tracks the current top of the stack. If the stack pointer meets the heap pointer (or hits RLIMIT_STACK), memory is exhausted.
The Unmapped Zone (0x00000000 – 0x08048000)
A critical but often overlooked part of the layout is the unmapped region from 0x00000000 up to 0x08048000 (128 MB on older 32-bit Linux).
- This area contains no code, no data, no stack, no heap.
- It is deliberately left unmapped by the OS.
Why does it exist?
To catch null pointer dereferences. If a program tries to access memory via a NULL pointer (address 0x0) or a small offset from it, the access falls into this unmapped region, triggering a segmentation fault — immediately crashing the process and preventing silent memory corruption.
Without this guard zone, dereferencing a null pointer could silently corrupt the Text, Data, or BSS segments, leading to unpredictable behavior.
Notes on Other Architectures
- On 64-bit Linux, the text segment typically starts at 0x00400000, but the unmapped guard zone at address zero remains.
- On some architectures, the stack may grow upward instead of downward.
- The exact split between user/kernel space can vary (e.g., 2 GB / 2 GB, 1 GB / 3 GB).
Further Reading
- Virtual Memory, Paging, and Swapping
- man proc (see /proc/[pid]/maps)
- execve(2) and brk(2) system calls
- ELF binary format specification