Out Of Memory Management
Out Of Memory Management
It has one simple task, check if there is enough available memory to satisfy, verify that the system is truely out of memory and if so, select a process to kill
Checking Available Memory
For certain operations, such as expaning the heap with brk() or remapping an address space with mremap(), the system will check if there is enough available memory to satisfy a request. Note that this is separate to the out_of_memory() path that is covered in the next section. This path is used to avoid the system being in a state of OOM if at all possible.
When checking available memory, the number of required pages is passed as a parameter to vm_enough_memory(). Unless the system administrator has specified that the system should overcommit memory, the mount of available memory will be checked. To determine how many pages are potentially available, Linux sums up the following bits of data:
- Total page cache as page cache is easily reclaimed
- Total free pages because they are already available
- Total free swap pages as userspace pages may be paged out
- Total pages managed by swapper_space although this double-counts the free swap pages. This is balanced by the fact that slots are sometimes reserved but not used
- Total pages used by the dentry cache as they are easily reclaimed
- Total pages used by the inode cache as they are easily reclaimed
If the total number of pages added here is sufficient for the request, vm_enough_memory() returns true to the caller. If false is returned, the caller knows that the memory is not available and usually decides to return -ENOMEM to userspace.
Determining OOM Status
When the machine is low on memory, old page frames will be reclaimed but despite reclaiming pages is may find that it was unable to free enough pages to satisfy a request even when scanning at highest priority. If it does fail to free page frames, out_of_memory() is called to see if the system is out of memory and needs to kill a process.
Unfortunately, it is possible that the system is not out memory and simply needs to wait for IO to complete or for pages to be swapped to backing storage. This is unfortunate, not because the system has memory, but because the function is being called unnecessarily opening the possibly of processes being unnecessarily killed. Before deciding to kill a process, it goes through the following checklist.
- Is there enough swap space left (nr_swap_pages > 0) ? If yes, not OOM
- Has it been more than 5 seconds since the last failure? If yes, not OOM
- Have we failed within the last second? If no, not OOM
- If there hasn’t been 10 failures at least in the last 5 seconds, we’re not OOM
- Has a process been killed within the last 5 seconds? If yes, not OOM
It is only if the above tests are passed that oom_kill() is called to select a process to kill.
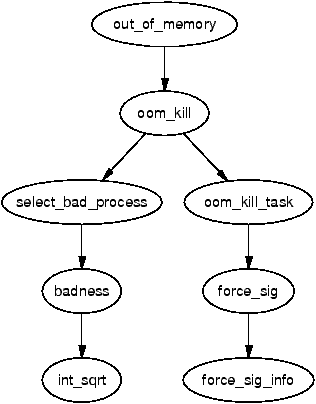
Selecting a Process
The function select_bad_process() is responsible for choosing a process to kill. It decides by stepping through each running task and calculating how suitable it is for killing with the function badness(). The badness is calculated as follows, note that the square roots are integer approximations calculated with int_sqrt();
badness_for_task = total_vm_for_task / (sqrt(cpu_time_in_seconds) * sqrt(sqrt(cpu_time_in_minutes)))
This has been chosen to select a process that is using a large amount of memory but is not that long lived. Processes which have been running a long time are unlikely to be the cause of memory shortage so this calculation is likely to select a process that uses a lot of memory but has not been running long. If the process is a root process or has CAP_SYS_ADMIN capabilities, the points are divided by four as it is assumed that root privilege processes are well behaved. Similarly, if it has CAP_SYS_RAWIO capabilities (access to raw devices) privileges, the points are further divided by 4 as it is undesirable to kill a process that has direct access to hardware.
Flow of Processing
- User process → malloc(), new, mmap(), fork()
- __alloc_pages() -> __alloc_pages_nodemask()
- __alloc_pages_slowpath() -> __alloc_pages_may_oom()
- out_of_memory()
- select_bad_process() -> oom_evaluate_task()
- oom_badness()
- oom_kill_process()
- SIGKILL → Victim process
- Memory freed → System continues
__alloc_pages()
1
2
3
4
5
static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid)
{
return __alloc_pages_nodemask(gfp_mask, order, preferred_nid, NULL);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (unlikely(order >= MAX_ORDER)) {
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
gfp_mask &= gfp_allowed_mask;
alloc_mask = gfp_mask;
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))
return NULL;
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask);
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}.
*/
alloc_mask = current_gfp_context(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}
EXPORT_SYMBOL(__alloc_pages_nodemask);
__alloc_pages_slowpath()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
/*
* We also sanity check to catch abuse of atomic reserves being used by
* callers that are not in atomic context.
*/
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
cpuset_mems_cookie = read_mems_allowed_begin();
/*
* The fast path uses conservative alloc_flags to succeed only until
* kswapd needs to be woken up, and to avoid the cost of setting up
* alloc_flags precisely. So we do that now.
*/
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
* We need to recalculate the starting point for the zonelist iterator
* because we might have used different nodemask in the fast path, or
* there was a cpuset modification and we are retrying - otherwise we
* could end up iterating over non-eligible zones endlessly.
*/
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->highest_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
/*
* The adjusted alloc_flags might result in immediate success, so try
* that first
*/
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/*
* For costly allocations, try direct compaction first, as it's likely
* that we have enough base pages and don't need to reclaim. For non-
* movable high-order allocations, do that as well, as compaction will
* try prevent permanent fragmentation by migrating from blocks of the
* same migratetype.
* Don't try this for allocations that are allowed to ignore
* watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen.
*/
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* Checks for costly allocations with __GFP_NORETRY, which
* includes some THP page fault allocations
*/
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
/*
* If allocating entire pageblock(s) and compaction
* failed because all zones are below low watermarks
* or is prohibited because it recently failed at this
* order, fail immediately unless the allocator has
* requested compaction and reclaim retry.
*
* Reclaim is
* - potentially very expensive because zones are far
* below their low watermarks or this is part of very
* bursty high order allocations,
* - not guaranteed to help because isolate_freepages()
* may not iterate over freed pages as part of its
* linear scan, and
* - unlikely to make entire pageblocks free on its
* own.
*/
if (compact_result == COMPACT_SKIPPED ||
compact_result == COMPACT_DEFERRED)
goto nopage;
/*
* Looks like reclaim/compaction is worth trying, but
* sync compaction could be very expensive, so keep
* using async compaction.
*/
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = current_alloc_flags(gfp_mask, reserve_flags);
/*
* Reset the nodemask and zonelist iterators if memory policies can be
* ignored. These allocations are high priority and system rather than
* user oriented.
*/
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->nodemask = NULL;
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->highest_zoneidx, ac->nodemask);
}
/* Attempt with potentially adjusted zonelist and alloc_flags */
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/*
* Do not retry costly high order allocations unless they are
* __GFP_RETRY_MAYFAIL
*/
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
/*
* It doesn't make any sense to retry for the compaction if the order-0
* reclaim is not able to make any progress because the current
* implementation of the compaction depends on the sufficient amount
* of free memory (see __compaction_suitable)
*/
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* Deal with possible cpuset update races before we start OOM killing */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* Reclaim has failed us, start killing things */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */
if (tsk_is_oom_victim(current) &&
(alloc_flags & ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* Retry as long as the OOM killer is making progress */
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/* Deal with possible cpuset update races before we fail */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/*
* Make sure that __GFP_NOFAIL request doesn't leak out and make sure
* we always retry
*/
if (gfp_mask & __GFP_NOFAIL) {
/*
* All existing users of the __GFP_NOFAIL are blockable, so warn
* of any new users that actually require GFP_NOWAIT
*/
if (WARN_ON_ONCE(!can_direct_reclaim))
goto fail;
/*
* PF_MEMALLOC request from this context is rather bizarre
* because we cannot reclaim anything and only can loop waiting
* for somebody to do a work for us
*/
WARN_ON_ONCE(current->flags & PF_MEMALLOC);
/*
* non failing costly orders are a hard requirement which we
* are not prepared for much so let's warn about these users
* so that we can identify them and convert them to something
* else.
*/
WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER);
/*
* Help non-failing allocations by giving them access to memory
* reserves but do not use ALLOC_NO_WATERMARKS because this
* could deplete whole memory reserves which would just make
* the situation worse
*/
page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);
if (page)
goto got_pg;
cond_resched();
goto retry;
}
fail:
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}
__alloc_pages_may_oom()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
static inline struct page *
__alloc_pages_may_oom(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac, unsigned long *did_some_progress)
{
struct oom_control oc = {
.zonelist = ac->zonelist,
.nodemask = ac->nodemask,
.memcg = NULL,
.gfp_mask = gfp_mask,
.order = order,
};
struct page *page;
*did_some_progress = 0;
/*
* Acquire the oom lock. If that fails, somebody else is
* making progress for us.
*/
if (!mutex_trylock(&oom_lock)) {
*did_some_progress = 1;
schedule_timeout_uninterruptible(1);
return NULL;
}
/*
* Go through the zonelist yet one more time, keep very high watermark
* here, this is only to catch a parallel oom killing, we must fail if
* we're still under heavy pressure. But make sure that this reclaim
* attempt shall not depend on __GFP_DIRECT_RECLAIM && !__GFP_NORETRY
* allocation which will never fail due to oom_lock already held.
*/
page = get_page_from_freelist((gfp_mask | __GFP_HARDWALL) &
~__GFP_DIRECT_RECLAIM, order,
ALLOC_WMARK_HIGH|ALLOC_CPUSET, ac);
if (page)
goto out;
/* Coredumps can quickly deplete all memory reserves */
if (current->flags & PF_DUMPCORE)
goto out;
/* The OOM killer will not help higher order allocs */
if (order > PAGE_ALLOC_COSTLY_ORDER)
goto out;
/*
* We have already exhausted all our reclaim opportunities without any
* success so it is time to admit defeat. We will skip the OOM killer
* because it is very likely that the caller has a more reasonable
* fallback than shooting a random task.
*
* The OOM killer may not free memory on a specific node.
*/
if (gfp_mask & (__GFP_RETRY_MAYFAIL | __GFP_THISNODE))
goto out;
/* The OOM killer does not needlessly kill tasks for lowmem */
if (ac->highest_zoneidx < ZONE_NORMAL)
goto out;
if (pm_suspended_storage())
goto out;
/*
* XXX: GFP_NOFS allocations should rather fail than rely on
* other request to make a forward progress.
* We are in an unfortunate situation where out_of_memory cannot
* do much for this context but let's try it to at least get
* access to memory reserved if the current task is killed (see
* out_of_memory). Once filesystems are ready to handle allocation
* failures more gracefully we should just bail out here.
*/
/* Exhausted what can be done so it's blame time */
if (out_of_memory(&oc) || WARN_ON_ONCE(gfp_mask & __GFP_NOFAIL)) {
*did_some_progress = 1;
/*
* Help non-failing allocations by giving them access to memory
* reserves
*/
if (gfp_mask & __GFP_NOFAIL)
page = __alloc_pages_cpuset_fallback(gfp_mask, order,
ALLOC_NO_WATERMARKS, ac);
}
out:
mutex_unlock(&oom_lock);
return page;
}
out_of_memory()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
/**
* out_of_memory - kill the "best" process when we run out of memory
* @oc: pointer to struct oom_control
*
* If we run out of memory, we have the choice between either
* killing a random task (bad), letting the system crash (worse)
* OR try to be smart about which process to kill. Note that we
* don't have to be perfect here, we just have to be good.
*/
bool out_of_memory(struct oom_control *oc)
{
unsigned long freed = 0;
if (oom_killer_disabled)
return false;
if (!is_memcg_oom(oc)) {
blocking_notifier_call_chain(&oom_notify_list, 0, &freed);
if (freed > 0)
/* Got some memory back in the last second. */
return true;
}
/*
* If current has a pending SIGKILL or is exiting, then automatically
* select it. The goal is to allow it to allocate so that it may
* quickly exit and free its memory.
*/
if (task_will_free_mem(current)) {
mark_oom_victim(current);
wake_oom_reaper(current);
return true;
}
/*
* The OOM killer does not compensate for IO-less reclaim.
* pagefault_out_of_memory lost its gfp context so we have to
* make sure exclude 0 mask - all other users should have at least
* ___GFP_DIRECT_RECLAIM to get here. But mem_cgroup_oom() has to
* invoke the OOM killer even if it is a GFP_NOFS allocation.
*/
if (oc->gfp_mask && !(oc->gfp_mask & __GFP_FS) && !is_memcg_oom(oc))
return true;
/*
* Check if there were limitations on the allocation (only relevant for
* NUMA and memcg) that may require different handling.
*/
oc->constraint = constrained_alloc(oc);
if (oc->constraint != CONSTRAINT_MEMORY_POLICY)
oc->nodemask = NULL;
check_panic_on_oom(oc);
if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task &&
current->mm && !oom_unkillable_task(current) &&
oom_cpuset_eligible(current, oc) &&
current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) {
get_task_struct(current);
oc->chosen = current;
oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)");
return true;
}
select_bad_process(oc);
/* Found nothing?!?! */
if (!oc->chosen) {
dump_header(oc, NULL);
pr_warn("Out of memory and no killable processes...\n");
/*
* If we got here due to an actual allocation at the
* system level, we cannot survive this and will enter
* an endless loop in the allocator. Bail out now.
*/
if (!is_sysrq_oom(oc) && !is_memcg_oom(oc))
panic("System is deadlocked on memory\n");
}
if (oc->chosen && oc->chosen != (void *)-1UL)
oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" :
"Memory cgroup out of memory");
return !!oc->chosen;
}
select_bad_process()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/*
* Simple selection loop. We choose the process with the highest number of
* 'points'. In case scan was aborted, oc->chosen is set to -1.
*/
static void select_bad_process(struct oom_control *oc)
{
oc->chosen_points = LONG_MIN;
if (is_memcg_oom(oc))
mem_cgroup_scan_tasks(oc->memcg, oom_evaluate_task, oc);
else {
struct task_struct *p;
rcu_read_lock();
for_each_process(p)
if (oom_evaluate_task(p, oc))
break;
rcu_read_unlock();
}
}
oom_evaluate_task()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
static int oom_evaluate_task(struct task_struct *task, void *arg)
{
struct oom_control *oc = arg;
long points;
if (oom_unkillable_task(task))
goto next;
/* p may not have freeable memory in nodemask */
if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc))
goto next;
/*
* This task already has access to memory reserves and is being killed.
* Don't allow any other task to have access to the reserves unless
* the task has MMF_OOM_SKIP because chances that it would release
* any memory is quite low.
*/
if (!is_sysrq_oom(oc) && tsk_is_oom_victim(task)) {
if (test_bit(MMF_OOM_SKIP, &task->signal->oom_mm->flags))
goto next;
goto abort;
}
/*
* If task is allocating a lot of memory and has been marked to be
* killed first if it triggers an oom, then select it.
*/
if (oom_task_origin(task)) {
points = LONG_MAX;
goto select;
}
points = oom_badness(task, oc->totalpages);
if (points == LONG_MIN || points < oc->chosen_points)
goto next;
select:
if (oc->chosen)
put_task_struct(oc->chosen);
get_task_struct(task);
oc->chosen = task;
oc->chosen_points = points;
next:
return 0;
abort:
if (oc->chosen)
put_task_struct(oc->chosen);
oc->chosen = (void *)-1UL;
return 1;
}
oom_badness()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/**
* oom_badness - heuristic function to determine which candidate task to kill
* @p: task struct of which task we should calculate
* @totalpages: total present RAM allowed for page allocation
*
* The heuristic for determining which task to kill is made to be as simple and
* predictable as possible. The goal is to return the highest value for the
* task consuming the most memory to avoid subsequent oom failures.
*/
long oom_badness(struct task_struct *p, unsigned long totalpages)
{
long points;
long adj;
if (oom_unkillable_task(p))
return LONG_MIN;
p = find_lock_task_mm(p);
if (!p)
return LONG_MIN;
/*
* Do not even consider tasks which are explicitly marked oom
* unkillable or have been already oom reaped or the are in
* the middle of vfork
*/
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN ||
test_bit(MMF_OOM_SKIP, &p->mm->flags) ||
in_vfork(p)) {
task_unlock(p);
return LONG_MIN;
}
/*
* The baseline for the badness score is the proportion of RAM that each
* task's rss, pagetable and swap space use.
*/
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +
mm_pgtables_bytes(p->mm) / PAGE_SIZE;
task_unlock(p);
/* Normalize to oom_score_adj units */
adj *= totalpages / 1000;
points += adj;
return points;
}
oom_kill_process()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
static void oom_kill_process(struct oom_control *oc, const char *message)
{
struct task_struct *victim = oc->chosen;
struct mem_cgroup *oom_group;
static DEFINE_RATELIMIT_STATE(oom_rs, DEFAULT_RATELIMIT_INTERVAL,
DEFAULT_RATELIMIT_BURST);
/*
* If the task is already exiting, don't alarm the sysadmin or kill
* its children or threads, just give it access to memory reserves
* so it can die quickly
*/
task_lock(victim);
if (task_will_free_mem(victim)) {
mark_oom_victim(victim);
wake_oom_reaper(victim);
task_unlock(victim);
put_task_struct(victim);
return;
}
task_unlock(victim);
if (__ratelimit(&oom_rs))
dump_header(oc, victim);
/*
* Do we need to kill the entire memory cgroup?
* Or even one of the ancestor memory cgroups?
* Check this out before killing the victim task.
*/
oom_group = mem_cgroup_get_oom_group(victim, oc->memcg);
__oom_kill_process(victim, message);
/*
* If necessary, kill all tasks in the selected memory cgroup.
*/
if (oom_group) {
mem_cgroup_print_oom_group(oom_group);
mem_cgroup_scan_tasks(oom_group, oom_kill_memcg_member,
(void*)message);
mem_cgroup_put(oom_group);
}
}
This post is licensed under CC BY 4.0 by the author.